The Secrets of Log Monitoring for the Curious SEO
When log monitoring and SEO come up, we hear lot about the value of crawl budget optimization, monitoring Googlebot behavior and tracking organic visitors. But here are a few of the gritty secrets that don’t get shared as often.
What is log monitoring?
In SEO, server records of requests for URLs can be used to learn more about how bots and people use a website. Web servers record every request, its timestamp, the URL that was requested, who requested it, and the response that the server provided.
Requests are logged in various formats, but most look something like this:
Bot visit, identified by the Googlebot user-agent and IP address:
www.oncrawl.com:80 66.249.73.145 – – [07/Feb/2018:17:06:04 +0000] “GET /blog/ HTTP/1.1” 200 14486 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)” “-”
Organic visit, identified by the Google address as the referer:
www.oncrawl.com:80 37.14.184.94 – – [07/Feb/2018:17:06:04 +0000] “GET /blog/ HTTP/1.1” 200 37073 “https://www.google.es/” “Mozilla/5.0 (Linux; Android 7.0; SM-G920F Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.137 Mobile Safari/537.36” “-”
Why logs are the key to SEO success
Log data provides concrete and un-aggregated figures to answer questions that are at the heart of SEO:
- How many of my pages have been explored by Google? By users coming from the SERPs?
- How often does Google (or organic visitors) visit my pages?
- Does Google (or organic visitors) visit some pages more than others?
- What URLs produce errors on my site?
Following patterns in Googlebot visits can also provide information about your site’s ranking and indexing. Drops in crawl frequency often precede ranking drops by 2-5 days; a peak in crawl behavior followed by an increase in mobile bot activity and a decline in desktop bot activity is a good sign you’ve moved to Mobile-First Indexing–even if you haven’t received the official email.
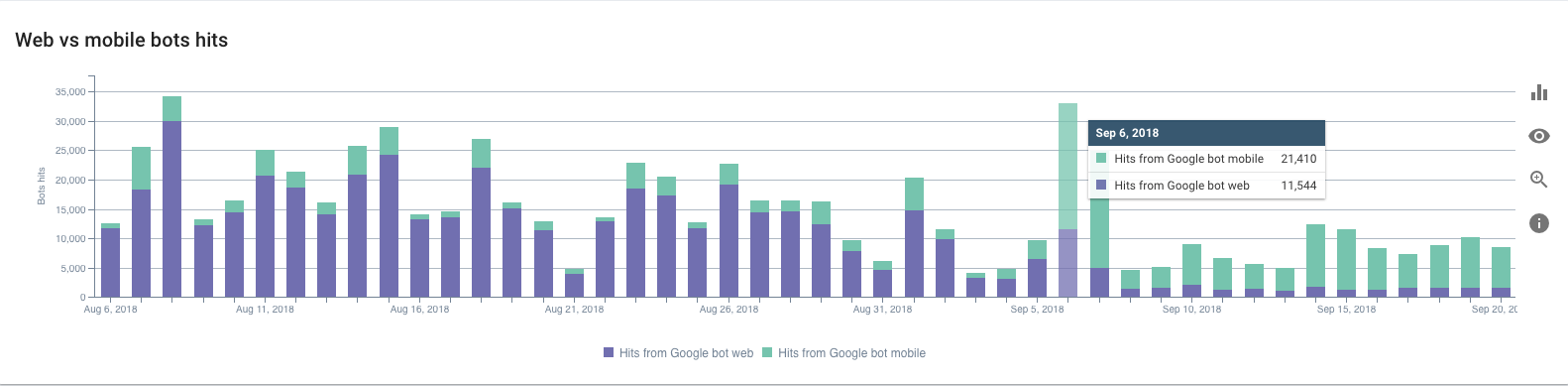
Example of a website that have switched to the mobile-first index
And if you’re having a hard time ranking pages, but they’ve never had a “hit” by a googlebot, you know it’s not worth your on-page SEO: Google doesn’t know what’s on the page yet.
Log data is also essential when analyzing crawl budget on groups of pages, when examining the relationship between crawl and organic traffic, or when understanding the relationship between on-page factors and behavior by bots and visitors.
Because this data comes directly from the server, the gatekeeper of access to a website, it is complete, definitive, always up-to-date, and 100% reliable.
Logs lines come in all shapes and sizes
Not all server logs are presented in the same format. Their fields might be in a different order They might not contain all of the same information.
Some information that is often not included in log files by default includes:
- The host. If you’re using your log files for SEO, this is extremely useful. It helps differentiate between requests for HTTP and HTTPS pages, and between subdomains of the same domain.
- The port. The port used to transfer data can provide additional information on the protocol used.
- The transfer time. If you don’t have other means of determining page speed, the time required to transfer all of the page content to the requester can be very useful.
- The number of bytes transferred. The number of bytes helps you spot unusually large or small pages, as well as unwieldy media resources.
Identifying bots is not always easy: the good, the bad, and the missing
Bad bots
Sometimes it’s hard to tell what’s a bot and what’s not. To identify bots, it’s best to start by looking at the user-agent, which contains the name of the visitor, such as “google” or “googlebot”.
But because Google uses legitimate bots to crawl websites, scammers and scrapers (who steal content from your website) often name their bots after Google’s in hopes that they won’t be caught.
Google recommends using reverse DNS lookup to check the IP addresses of their bots. They provide the range of IP addresses their bots use. Bots whose entire user-agent and IP address do not check out should be discounted, and–most likely–blocked.
This isn’t a rare case. Bad bots can account for over a quarter of the total website traffic on a typical site, according to this study from 2016.
Good bots
On the other hand, bot monitoring also produces some surprises: at OnCrawl, SEO experts often uncover new googlebots before they’re announced. Based on the type of pages they request, we’re sometimes able to guess their role at Google. Among the bots we identified before Google announced them are:
- [Ajax] : JavaScript crawler
- Google-AMPHTML: AMP exploration
- Google-speakr: crawls pages for Google’s page-reading service. It gained a lot of attention in early February 2019 as industry leaders tweeted about having noticed it.
Knowing what type of bot your site attracts gives you the keys to understanding how Google sees and treats your pages.
Missing bots
We’ve also discovered that, although Googlebot-News is still listed in the official list of bots, this bot is not used for crawling news articles. In fact, we’ve never spotted it in the wild.
Server errors disguised as valid pages
Sometimes server errors produce blank pages, but the server doesn’t realize this is an error. It reports the page as a status 200 (“everything’s ok!”) and no one’s the wiser–but neither bots nor visitors seeing blank pages get to see the URL’s actual content.
Monitoring the number of bytes transferred in server logs per URL will reveal this sort of error, if one occurs.
Hiding spots for orphan pages
Orphan pages, or pages that are not linked to from any other pages in your site’s structure, can be a major SEO issue. They underperform because link’s confer popularity and because they’re difficult for browsing users (and bots) to discover naturally on a website.
Any list of known pages, when examined with crawl data, can be useful for finding orphan pages. But few lists of pages are as complete as the URLs extracted from log data: logs contain every page that Google crawls or has tried to crawl, as well as every page visitors have visited or tried to visit.
Sharing with SEA
SEA (paid search engine advertising) also profits from log monitoring. GoogleAds verifies URLs associated with paid results using the following bots:
- AdsBot-Google
- AdsBot-Google-Mobile
The presence of these bots on your site can correspond with increases in spending and new campaigns.
What’s really behind Google’s crawl stats
When we talk about crawl budget, there are two sources for establishing your crawl budget:
- Google Search Console: in the old Google Search Console, a graph of pages crawled per day and an average daily crawl rate are provided under Crawl > Crawl Stats.
- Log data: the count of googlebot hits over a period of time, divided by the number of days in the period, gives another daily crawl rate.
Often, these two rates–which purportedly measure the same thing–are different values.
Here’s why:
- SEOs often only count hits from SEO-related bots (“googlebot” in its desktop and mobile versions)
- Google Search Console seems to provide a total for all of Google’s bots, whether or not their role is associated with SEO. This is the case of bots like AdSense (“Mediapartners-Google”), which crawls monetized pages on which Google places ads.
- Google doesn’t list all of its the bots or all of the bots included in its crawl budget graph.
This poses two main problems:
- The inclusion of non-SEO bots can disguise SEO crawl trends that are subsumed in activity by other bots. Drops in activity and unexpected peaks may look alarming, but have nothing to do with SEO; conversely, important SEO indicators may go unnoticed.
- As features and reports are phased out of the old Google Search Console, it can be nerve-wracking to rely on Google Search Console for such essential information. It’s difficult to say whether this report will remain available in the long term.
Basing crawl analysis on log data is a good way around these uncertainties.
Log data and the GDPR
Under the European Union’s GDPR, the collecting, storing, and treatment of personal data is subject to extra safety care and protocols. Log data may fall in a gray zone under this legislation: in many cases, the European Commission considers IP address of people (not bots) to be personal information.
Some log analysis solutions, including OnCrawl, offer solutions for this issue. For example, OnCrawl has developed tools that strip IP addresses from log lines that do not belong to bots in order to avoid storing and processing this information unnecessarily.
TL;DR Log data isn’t just about crawl budget
There are plenty of secrets you don’t often hear mentioned in discussions about log files.
Here are the top ten takeaways:
- Log data is the only 100% reliable source for all site traffic information.
- Make sure your server logs the data you’re interested in–not all data is required in logs.
- Verify that bots that look like Google really are Google.
- Monitoring the different Google bots that visit your site allows you to discover how Google crawls.
- Not all official Googlebots are active bots.
- In addition to 4xx and 5xx HTTP status codes, keep an eye out for errors that serve empty pages in 200.
- Use log data to uncover orphan pages.
- Use log data to track SEA campaign effets.
- Crawl budget and crawl rate is best monitored using log data.
- Be aware of privacy concerns under the GDPR.
Rebecca works at OnCrawl who were the headline sponsors at Search London’s 8th birthday party. They are still offering an exclusive 30 day free trial or visit OnCrawl at www.oncrawl.com to find out more.