There is a large community in London for any industry (not just search) as it is one of the top destinations for work, travel and study. The search community when I started out was big and organizers had to check that they did not have an event the same day or night as another search meetup. Some meetups have changed from when I first took over Search London at the end of 2010 and others have stopped while others have grown considerably. I took over the group which was called SEO SMO and PPC from Judith Lewis. I had wanted to take part in the SEO community and run an event for those in our industry as there is always news to read, changes to keep up with and it is a very young industry. Now we have had over 80 events and there are more than 2800 members. We have our own website, Twitter and Linkedin page.
Search London is not just for those in SEO, but for people who work in PPC and Social Media too. The aim of Search London when I set it up, was to provide a platform for first time speakers, those in the search industry to share their experience and get support from others. These objectives still ring true today and I want to ensure that those who present at Search London, there is always at least one first time speaker (normally we have 2 presenters per event).

From the outset I wanted to ensure Search London a safe space especially for newbies in the industry. Many of us have experienced toxic work environments and places where we are not supported. I therefore wanted to create a safe space for those in our industry where they could ask questions without fear of being reprimanded or made to feel inferior or have our confidence knocked down. I also wanted to give opportunities to those who wanted to gain experience in presenting. Then when I wanted to get start speaking at events, I was told I did not have experience, but in order to gain this, someone needs to give you the opportunity. Therefore I wanted to do give the speaking opportunities to others.
We speak about a wide variety of topics, many search related but we also keep it topical such as avoiding stress at work when back in the office and also How to be an LGBTQ+ Ally in Marketing.
Speakers
I have always encouraged first time speakers and many have gone on to present at BrightonSEO and other bigger events. We have a variety of presenters from small agencies, those who are freelance and those who work for themselves and who work client side. Some of the people who have presented include:
Ebere Jonathan, Sarah McDowell, Kesar Rana , Judith Lewis, Tazmin Suleman, Aleyda Solis, Azeem Ahmad, Jamie White, Rejoice Ojiaku, Owain Lloyd-Williams, Ulrika Viberg, Silvia Martin, Adrijana Vujadin, Mathilde Høj, Aymen Loukil, Sophie Moule, Samuel Mangialavori , Lexi Mills, Chris Green , Charlie Williams, Nichola Stott, Kevin Gibbons, Paddy Moogan , Kirsty Hulse , Helen Pollitt , Arianne Donoghue, Gordon Campbell, Swapnil Pate, Sara Taher, Briony Gunson, Nathan Abbott and Serena Pearson.

At our April 2023 event (photo above), we had a very international Search London. We had Kristina Azarenko from Canada, Himani Kankaria from India, Jamie White from the UK and Chris Walsh from New Zealand. It was also the first time my husband was able to join Search London, he is from Bolivia and is also Spanish. In our June event in 2023, all of our speakers were from outside the UK.
Mix of online and in person
In 2023, Search London in person events were organised every other month (except over the summer of 2023) and the online events were organised the other months. Many of the speakers at Search London online are those who do not live in the city or who cannot get to London. The events are hosted using a platform called Remo with the sessions recorded and sent to those who attend the online events.
Anniversaries and parties
I always like to celebrate birthday parties and since (and including our 5th birthday) we have celebrated every year). Normally we hold the birthday parties in January or February but due to the pandemic we held our 11th birthday in April 2022. Our 10th birthday party was online. We had our 13th birthday at Bounce in February 2024 and had recorded talks by RO Pictures.
Past Sponsors
We have been lucky to have many sponsors support us throughout our 13 years. These are just some of the companies who have sponsored us.
Advanced Web Ranking, Bidnamic, Chillisauce, Conductor, DeepCrawl, Found, Google, inLinks, Kaizen, Majestic, OnCrawl, Pi Datametrics, Paper Gecko, Searchmetrics, Secret Escapes, SE Ranking, Sharp Ahead, Tela, Trainline, Webcertain, Wise, Uswitch, Vodafone, Wix, Yard, Yext
Some of the benefits of sponsoring including:
- Promoting your brand in front of a targeted audience
- 100 digital marketing professionals attending the birthday parties
- Brand emailed to 2300+ search professionals (via meetup)
- Search LDN posts are shared on average 20 times
- Marketing of your brand for before the event to a targeted audience, during and after the event.
2024 Plans and Growth
We will continue to have more online and in person events for Search London. We are looking for parnters to help us plan events ore in advance. Contact me on @SEOJoBlogs if you would like to be involved. The partnership presentation can be viewed here in English and here in Spanish.
Search Barcelona
I am now running Search Barcelona and we had our first event on June 28th 2023 in Barcelona which SE Ranking and WebCertain sponsored. Here are a few photos of the event. I organised a second event in November and then the latest Search Barcelona May 10th, this year at the Cotton House Hotel. We will also have a dinner in the summer with a group of Digital Marketing Professionals.
Pitching to speak
Search London and Search Barcelona are always looking for first time speakers. Submit your talk here for either event and we will come back to you. We will have events in September 2024 in London and October in Barcelona.
Other Search Events in London
Women in Tech SEO
I went to the first Women in Tech SEO event in June 2019. I knew as soon as Areej AbuAli announced it, this was going to be big. When Areej puts her mind to something, she is dedicated and goes above and beyond. Areej is very focused and grew her community to now over 6,000 global members and there are over 40k followers on social media.
I was lucky enough to be asked to be a volunteer at two of the Women in Tech SEO Festivals and I have been to every WTSFest since it launched in March 2020. It was the last in person event I attended before the lockdown happened.
Areej has a code of conduct that everyone follows. This is so important and the community values are:
- To be kind
- To be helpful
- To be respectful
- To be a safe and judgment-free community
The last one particularly resonates with me. In the search community, it is important that we can be part of a judgment-free environment. Many of us unfortunately are party to toxic work environments where we have been judged.
There are so many initiatives Areej is running outside of WTSFest. This has been the fourth year to run the WTS Mentorship program. Areej set up the Women in Tech SEO workshops, starting in October 2019 and recently kicked off again the WTSEO podcast series which started in April 2021. There are also interviews with many of those in the WTSEO community as well as a newsletter that goes to over 3,000 subscribers. In June 2023, Areej introduced WTSKnowledge which brings a new perspective to the world of news and education in SEO. The knowledge hub amplifies the expertise of underrepresented voices across a range of topics in SEO.
WTS has a huge community, in person as well as on Slack and on Facebook. I am blown away by how Areej has managed to set this up while working full time, grow this and develop it into one of the best search communities.
2024 Plans and Growth
WTS has already gone Stateside in 2023. After setting up in London in March 2020, it had its first US event September 21st 2023. Last week (June 7th), there was WTSFest Berlin and the next US event will be in September 2024.

Photo from Kaye Ford at WTSFest Berlin
How can you get involved?
You can get involved by being a partner too but you can also buy them a coffee. Another key thing that sets WTSEO from other conferences is that Areej pays speakers. This is a first as many large conferences that are solely dedicated to running events do not pay their speakers. WTS can do this as they feel this is important (and so it is). They also have partners that support them.
PPC Live

PPC Live is run by Anu Adegbola and she started working on it in April 2022 with the first event being July 2022.
Anu set it up as she didn’t know of any other fun PPC networking event that was really built around community. The events are run once a quarter.
There have been various sponsors such as Founders, AdWorldExperience, ClickTech, MarinSoftware, Diginius, Victress Digital, Platypus Digital but there is plenty of room for others to get involved.
Anu mostly runs this on her own but she does have some amazing people who help a lot such as invaluable consistent help from the team at Victress Digital.
Speakers
One of PPC Live’s key values is Diversity. Anu has worked on looking for a different variety of people than those you would have seen spoken. She is looking for some of the experts you would have seen but also balance with those you don’t see, especially women, people of colour, first time speakers.
There is a long list like Gemma Russell, Rand Fishkin, Crystal Carter, Freya Jones, Sophie Logan, Azeem Ahmad, Chris Ridley and more. You can see the full list here – https://www.ppcliveuk.com/blog-feed.xml
Anu looks for expertise and passion. There is no good or bad speaker – there are just those who are passionate about a topic or not. A bonus is someone who clearly prepare well.
How to get involved to speak
There is an easy form to fill here. Anu will come back to you either way.
Plans for the rest of 2024 and beyond
Anu already had a great event in Brighton in April and will have another one in Manchester at the end of join. She plans to continue to grow the community through the newsletter, their Slack channel and the WhatsappGroup
Anu is always looking for people to support with PPC Live UK and they’re looking for sponsors to sponsor their events especially on a long-term basis. So if you’re interested in partnering with PPC LIve and for your brand to be seen by people who love PPC and are loyal to our events please email [email protected] to get a proposal.
FCDC – Freelance Coalition for Developing Countries
Chima Mmeje set up the FCDC and first started thinking about this initiaive in 2020. Earlier that year, she lost all her clients and had to figure out a rebranding strategy. Mentors were instrumental in choosing a niche, revamping her website, learning how to market my services better and closing sales calls. Towards the end of 2020, business picked up and she immediately wanted to pay it forward.
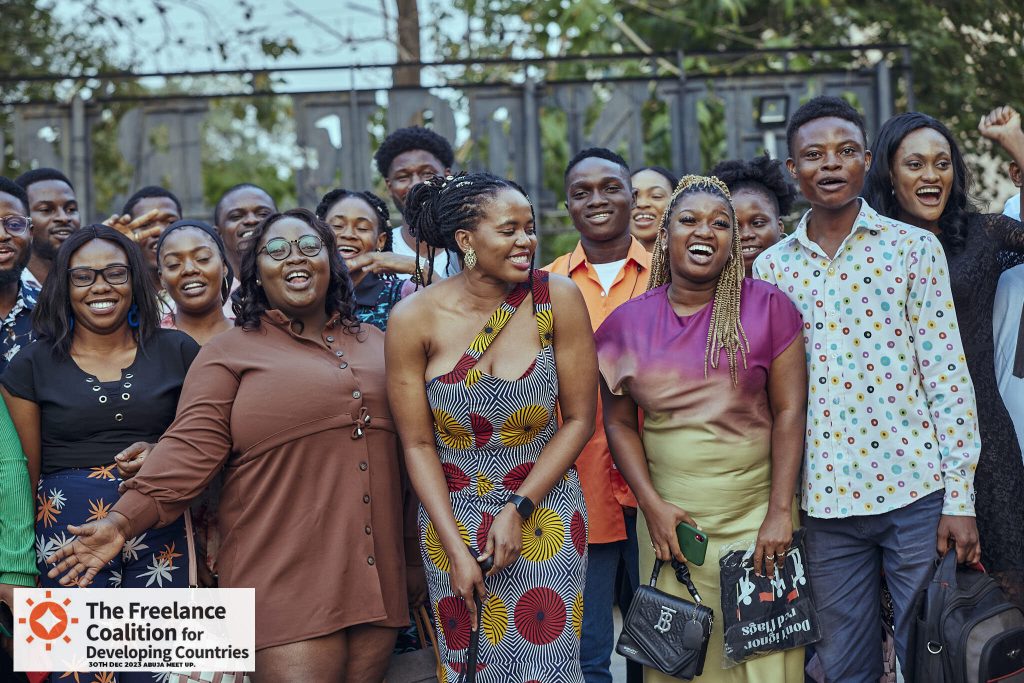
Photo is from the FCDC event in January 2024
Reason for setting up the FCDC
There’s so much she wouldn’t know without mentors. Chima initially set up the FCDC as a way for BIPOC copywriters to get support. It started on a spreadsheet and snowballed from there. Today, the mission has evolved to providing learning resources and support for BIPOC marketers who want to upskill or learn a new digital skill as a way to increase their income.
Meetups
The FCDC don’t meet often. It’s difficult to organize in-person meetups in the UK, but they meet as a community during BrightonSEO. It’s been one of the most rewarding parts of running the FCDC – providing access for community members to attend industry events, network and get inspired to possibly speak at a future event.
There was a meetup in Nairobi, during the summer of 2021 and they had a big meetup in Lagos, Nigeria, in January 2024. Chima would love to organize more meetups for their community members in Asia, specifically places like India and the Philippines where we have a lot of members.
How can sponsors get involved?
Getting sponsors for the FCDC initiatives is one of the most difficult parts of running a nonprofit. They usually have sponsors for specific initiatives. For example, Ahrefs was a partner for their Tech SEO cohort in 2021 while Tyler Hakes and the Optimist team partnered to sponsor Pride month at The FCDC last year and RicketyRoo sponsored a cohort in 2023.
The FCDC would love to have more sponsors for initiatives like:
- Full or part cohorts sponsors for trainings where we equip BIPOC folks with digital marketing skills.
- FCDC Internship where agencies and companies provide a 3-month paid internship to students who’ve completed the live cohort training
- Mentors for the FCDC mentorship program that runs for two months
- Sponsors for Pride Month and Women History Month at the FCDC
- On-going financial support to keep the FCDC running, send more people to events like BrightonSEO and provide more free training resources
The team behind the FCDC
There is Chima and two salaried employees, one freelance video editor and a web developer, based in Nigeria. All communications are remote.
How can partners and other non sponsors get involved with the FCDC?
Please reach out to Chima through email – chima at the freelance coalition dot org. They would love to have sponsors for our 2024 initiatives including the internship program and cohort training. Some of our partners are individuals who make monthly donations that goes towards running the FCDC, so if you’d love to join the monthly donor program, here’s the PayPal link. You can also make a one-time donation if you’re more comfortable doing that. You can also sponsor an FCDC member to attend BrightonSEO in 2024. It’s an ongoing initiative that’s entirely donor-led, so please get involved.
Plans for the rest of 2024
Do more of what they currently do!
Chima would love to partner with more course creators to provide free access to their paid courses for our community members, many of whom can’t afford to pay for these resources. It’s something they did successfully in 2021, where they distributed over a 1,000 courses and training resources to their members.
Chima is also thinking of ways to include community-led content so folks who follow our socials can see how the work we do impacts the community.
Search n Stuff
One of Yagmur Simsek’s lifelong aspirations has always been to create a special community where she could provide valuable support to both budding and established marketers or startups within the industry, fostering their growth and development. Her inspiration for this endeavor stemmed from her experiences attending SEO meetups and conferences ever since her move to London in 2020. Being a part of an inclusive search community had a profound impact on her personal growth. It introduced her to inspiring individuals who not only motivated her to push her boundaries but also helped her recognize her untapped potential and capabilities.

Photo is of some of the attendees at the Search n Stuff dinner in March 2024
Reasons for setting up Search n Stuff
Yagmur came up with the idea in April 2023 of establishing a new, updated version of community events, a platform through which she could finally give back all the support and encouragement Yagmur had received. During the process of brainstorming a name for this community, she decided that its scope should be beyond just SEO. She thought: “Why not keep it simple and call it ‘Search ‘n Stuff’?” and it continues to resonate with her more and more each passing day.
Meetups
The event is not limited for only search marketers; they aim to extend their reach. Yagmur’s plans would also include organizing various workshops catered to startups and the marketing teams of these startups. This way, they won’t only be sharing insights amongst ourselves, but also channeling our expertise to help companies of all sizes thrive in the realm of search marketing!
What initially began as a simple idea for periodic dinner networking events, organized on a monthly or bi-monthly basis, has evolved into something more diverse and exciting.
Plans for 2024 and beyond
Search ‘n Stuff is hosting its first conference in Turkey on October 11-12, 2024, at Akra Hotels in Antalya, focusing on SEO, PPC, social marketing, CRO, UX, FinTech, and Cyber Security, and more. Ticket options range from €360 for Access Only to €1,680 for Happy Together tickets, with various amenities, including accommodation, meals, VIP experiences, and networking opportunities. Antalya, known for its beautiful scenery and azure waters, will host this event, which promises to bring together some of the brightest minds in digital marketing.
The conference is designed to empower and inspire, with a mission to champion digital marketing enthusiasts, featuring panel discussions in both Turkish and English.
Attendees can expect practical tips and workshops on various digital marketing topics, including social media law, AI, digital PR, content marketing, and UX.
The event will feature 35+ international speakers and 250+ attendees from 5 different countries, covering 20 areas of digital interest with 15 workshops. Buy your ticket here.

There are a lot of search events in London to attend and it is a fantastic place to meet and learn from others in our industry. If you are a company, get involved and be part of these communities. Some grow quickly, while others may take some time but for many organisers this is something they do in their own free time. Many events do not make a lot of money (sometimes enough to cover costs) and they are being organised as they want to give something back to the community or build their own. You can help by providing a space for the organisers to host their event (especially if for under 50 people), sponsoring their events or paying for key aspects such as the food, drinks or for the filming and photography of the conference/meetup.